


Authorization in microservice architecture, P2: The approaches
A fined-grain access control model with the new architecture

In the previous part, we identified two main shortcomings of the old implementation:
The “coarse-grained” access control models.
The evolution of technical stack problem
Let's delve into the access control model. Access control model defines how permissions are granted, managed, and enforced within a system for users. It establishes the rules and structures that govern access rights and ensure secure operations. While Role-Based Access Control (RBAC) and Discretionary Access Control (DAC) are intuitive for users, they are too coarse-grained to manage access for every single resource for the system. Engineers often have to write custom code to gather information from user roles, access control lists, and various relationships between users and resources to determine permissions.
Assembling multiple access control models with custom code in a non-standard way becomes a management burden over time. Therefore, A single, more fine-grained solution will help us to meet the new demands of the system.
A Fine-Grained Authorization (FGA) system will allow granting specific users permission to perform certain actions on specific resources, simplify the management of permissions for millions of objects and users. FGA enables grouping individual pieces of authorization logic into higher-level concepts, managing permissions in a formalized framework. This standardizes the implementation of permission checking code for engineers. There are two popular FGA models: Relationship-Based Access Control (ReBAC) and Attribute-Based Access Control (ABAC)
Relationship based access control(ReBAC)
We learned about Relationship-Based Access Control (ReBAC) through Google Zanzibar paper. Unlike Role-Based Access Control, where developers model access around roles and their assignment to users or groups, ReBAC focuses on the relationships between all authorization entities in the system. It aims to build a graph of entities and permissions.
Back to the previous example, given User U1 belongs to Group G1, which monitors Group G2. Group G2 contains Group G3, G4. Evidence E1, E2, E3, E4 belongs to Case C1, if Case C1 is shared with Group G3 with view permission, below is the graph relationship:

Then, when asking 'Can User U1 view Evidence E1?', the service will find the relationship between the subject (U1) and the object (E1) from the defined graph. However, at that time, there was no popular implementation of this model. Besides that, following the paper, an efficient ReBAC system would require indexing all relationships of existing entities from the current system into a new graph database. It would introduce more dependencies to the system and also create consistency problems due to delays in syncing from the main operational database to the graph database.
Attribute based access control(ABAC)
ABAC, a better-known model at that time, models all authorization logic based on attributes of related entities in an enforcement request, such as subject, object, and environment. ABAC is flexible; developers can use roles, relationships, subject attributes, object attributes, time, IP, location, and more as attributes for policy writing. This allows us to continue using RBAC and DAC models within ABAC. In some documents, this approach is called “Attribute-Centric”. Customers can work with ACL and Role-Permission Management UI, while engineers have a new standard for implementing and deploying authorization logic.
Typically, the access policies in ABAC are expressed using logical conditions and attributes, offering greater expressiveness and precision in defining access controls.
Back to the example in ReBAC session above, the ABAC policy can be expressed like this:
request:
subject: "user"
resource: "evidence"
---
rules:
- user.permissions contains "evidence.view"
- evidence.throughCasesACL intersect user.monitoringGroupsHere:
evidence.throughCasesACL is an attribute of evidence E1, with the value "G3". This is because G3 is in the ACL of Case C1, and C1 contains E1.
user.monitoringGroups is an attribute of user U1, representing all groups that U1 is monitoring, which include G2, G3, and G4.
user.permissions is the list of scopes which is extracted from user’s JWT
The intersection of these groups returns the value G3, indicating that User U1 can view Evidence E1.
The approach
The ReBAC architecture sounds like an interesting and modern approach. The centralized graph entities database offers many benefits and makes finding relationships between subjects and objects much easier. This makes it a good fit for a heavily read system like an authorization service. This feature was also valuable when debugging or querying the list of users who could access a given piece of evidence to show in the UI.
However, the drawbacks of ReBAC made it unsuitable for our use case. As mentioned above, indexing all the entities from all product databases into a graph database and keeping them in sync would have been a huge task for our small team of just 2-3 engineers. It would also have made the entire data flow more complex for the existing system.
Moreover, some actions in Axon's product require strong consistency, meaning that as soon as a resource becomes available in the system, it should immediately have its own permissions for other tasks. The ReBAC data flow doesn't seem to fit this requirement.
On the other hand, ABAC seems a simpler approach. Engineers could use the existing data of Axon's products and model the attributes directly in these data. The policy engine in an ABAC system is normally stateless, which made it easier for engineers to test and migrate the authorization logic safely. With the Attribute-Centric approach, customers didn't need to learn anything new, they can continue to use the Role and ACL, while engineers had a better way to model the access control system.
Additionally, ABAC was a proven solution and there were several implementations at that time, making it a safer and better choice for us.
The ABAC architecture
Fortunately, The ABAC architecture guideline is also clear and flexible for any design, it breaks down the implementation into several components, each responsible for a specific task:
Policy Administration Point(PAP) manages access authorization policies
Policy Decision Point(PDP) evaluates access requests against authorization policies before issuing access decisions
Policy Information Point(PIP) provides the attribute values from external sources such as LDAP, databases, other services.
Policy Enforcement Point(PEP) inspects the request and generates an authorization request from which it sends to the PDP.
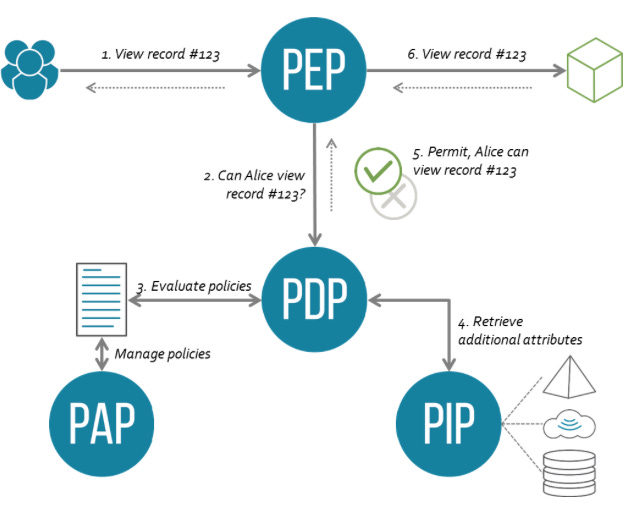
This image shows the ABAC architecture and a sample authorization flow:
A user sends a request which is intercepted by the Policy Enforcement Point (PEP)
The PEP forwards the authorization request to the Policy Decision Point (PDP)
The PDP evaluates the authorization request against the predefined policies and the attribute values are provided by Policy Information Points(PIP). These policies are managed by the Policy Administration Point (PAP).
The PDP reaches a decision (Permit / Deny / NotApplicable / Indeterminate) and returns it to the PEP
Following the guide above, we can flexibly implement each of these components in the existing microservices. For example the implementation below

You can see:
The PDP Service loads predefined policies from the Agency Service, which acts as a Policy Administration Point.
When enforcing requests from Service 1 or Service 2, the Policy Engine retrieves attribute data from several Policy Information Points(PIPs). These could be databases or other resource services. The communication protocol could be gRPC, Thrift, HTTP, JBDC, etc. These resource services typically maintain a cache layer to optimize performance.
Service 1, Service 2, and other PDP clients act as Policy Enforcement Points, requesting permission checks from the PDP Service.
The PIP and PDP Service can communicate through the contract like this:
service PdpService {
rpc enforce (EnforceRequest) returns (EnforceResponse);
rpc enforceBatch (EnforceBatchRequest) returns (EnforceBatchResponse);
...
}
message EnforceRequest {
Id subject = 10;
Id resource = 20;
string action = 30;
map<string, string> authzContext = 40;
RequestContext requestContext = 50;
}
message EnforceResponse {
Error error = 10;
AccessResult result = 20;
}
...Generally, the separation of ABAC components helps to divide responsibilities within the Authorization System. It provides flexibility to deploy each component wherever it's deemed appropriate for the design.
The next aspects of the authorization system we need to discuss are:
How to choose the Policy Language for the Policy Engine
How to deploy PDP in a multi-cluster architecture
Part 0: Introduction
Part 1: The Motivation to Change
Part 2: The Approaches
Part 3: The Policy Language
Part 4: Production Deployment